
Baue intelligentere KI-Apps mit Model Router, Azure AI Foundry und .NET – dynamisches Routing von Anfragen ganz einfach umgesetzt. Die englische Version dieses Beitrags findet ihr auf Medium.
Einführung
Mit zunehmender Komplexität von KI-Anwendungen steigt auch der Bedarf an Flexibilität und Skalierbarkeit beim Einsatz unterschiedlicher Foundation-Modelle. Microsoft begegnet diesem Trend mit Azure AI Foundry – einer Plattform, die es Entwickler:innen einfacher macht, Foundation-Modelle zu entdecken, zu nutzen und zu verwalten. Darunter sind Modelle von OpenAI, Meta, Mistral und vielen anderen.
Ein zentrales Element dieser Plattform ist der Model Router – eine clevere Abstraktionsschicht, mit der du über einen einzigen Endpunkt mit mehreren Modellen gleichzeitig arbeiten kannst. Egal ob du einen Chatbot baust, Dokumente zusammenfasst oder Code generierst: Der Model Router sorgt dafür, dass deine Anfrage zum passenden Modell weitergeleitet wird – ganz nach deiner Konfiguration.
In diesem Beitrag zeige ich dir anhand eines praktischen Beispiels in C# mit dem offiziellen SDK, wie du den Model Router in Azure AI Foundry nutzen kannst.
Was ist Azure AI Foundry?
Azure AI Foundry ist eine zentrale Plattform innerhalb von Azure, die Entwickler:innen dabei unterstützt:
- Verschiedene Foundation-Modelle zu entdecken, zu bewerten und zu nutzen (z. B. OpenAI, Llama 2, Mistral usw.)
- Vertraute APIs mit intelligenter Routing-Funktion zu verwenden
- Modelle konform und mit voller Beobachtbarkeit bereitzustellen und zu verwalten
Die Plattform wurde entwickelt, um den Einstieg in generative KI zu erleichtern. Entwickler:innen können einfach über eine einheitliche Schnittstelle arbeiten – und Azure kümmert sich im Hintergrund um die gesamte Orchestrierung.
Was ist der Model Router?
Der Model Router in Azure AI Foundry funktioniert wie ein intelligenter Vermittler. Anstatt ein bestimmtes Modell direkt anzusprechen, richtest du deine Anfrage an den Model Router-Endpunkt. Dieser leitet die Anfrage dann basierend auf der konfigurierten Logik an das passende Modell weiter.
Dabei berücksichtigt der Router Faktoren wie Komplexität der Anfrage, Kosten und Leistung, um die beste Modellwahl zu treffen. So bekommst du hochwertige Ergebnisse bei gleichzeitig optimierten Kosten. In Tests von Microsoft konnten im Vergleich zur direkten Nutzung von GPT-4.1 Einsparungen von bis zu 60 % erzielt werden – bei ähnlich hoher Genauigkeit.
Aktuell verfügbare Modelle im Model Router:
- GPT-4.1, Modellversion: 2025–04–14
- GPT-4.1-Mini, Modellversion: 2025–04–14
- GPT-4.1-Nano, Modellversion: 2025–04–14
- o4-Mini, Modellversion: 2025–04–16
Model Router im Azure-Portal einrichten
Um loszulegen, öffne das Azure-Portal und navigiere zu deiner Azure AI Foundry-Ressource. Falls du noch keine hast, kannst du sie ganz einfach über die Suche nach „Azure AI Foundry“ erstellen und dem geführten Setup folgen.
Sobald du dich in deinem Foundry-Workspace befindest:
- Wechsle in den Bereich Deployments.
- Klicke auf „Models + endpoints“ und wähle „+ Deploy model“.
- Wähle „model-router“ aus der Liste der verfügbaren Modelle.
- Vergib einen Namen für den Router (z. B.
model-router). - Speichere die Konfiguration mit Bestätigen und Bereitstellen.
💡 Hinweis: Du musst die zugrunde liegenden Modelle nicht manuell bereitstellen. Azure kümmert sich im Hintergrund um die Bereitstellung und Verfügbarkeit, sobald du den Model Router verwendest.
C#-Konsolen-App zur Nutzung des Model Routers
Im Folgenden zeige ich dir eine einfache interaktive Konsolenanwendung in C#, mit der du:
- deinen Azure OpenAI-Endpunkt und API-Schlüssel eingeben kannst,
- den Namen deiner Model-Router-Bereitstellung angibst,
- in einer Endlosschleife mit der KI chatten kannst,
- und nach jeder Antwort die Token-Nutzung angezeigt bekommst.
Zur besseren Darstellung und Nutzererfahrung in der Konsole verwende ich eine kleine Hilfsklasse namens ConsoleHelper. Den vollständigen Quellcode findest du in meinem GitHub-Repository.
Die Hauptlogik steckt in der Datei Program.cs. Beim Start fragt die App die nötigen Konfigurationswerte ab: Azure OpenAI-Endpunkt, API-Schlüssel und Name des Model-Router-Deployments.
Sobald die Konfiguration abgeschlossen ist, startet die Anwendung eine Chat-Schleife. Dabei wird der komplette Verlauf an den Model Router gesendet – und die Antwort der KI wird in Echtzeit angezeigt. Am Ende jeder Nachricht bekommst du außerdem Infos darüber, welches Modell verwendet wurde und wie viele Tokens für Eingabe und Ausgabe verbraucht wurden.
using Azure.AI.OpenAI;
using ModelRouterSample.Utils;
using OpenAI.Chat;
using System.ClientModel;
using ChatMessage = OpenAI.Chat.ChatMessage;
Console.CancelKeyPress += (sender, e) =>
{
// Prevent the process from terminating immediately
e.Cancel = true;
// Inform the user that cancellation was detected (e.g., Ctrl+C)
ConsoleHelper.WriteToConsole(
$"{Environment.NewLine}" +
$"[yellow]Cancellation requested. Exiting...[/]");
// Exit the application gracefully with a success code (0)
Environment.Exit(0);
};
// Load configuration from user input
var (endpoint, apiKey, deploymentModel) = GetConfiguration();
// Create Azure OpenAI chat client
var chatClient = new AzureOpenAIClient(
new Uri(endpoint),
new ApiKeyCredential(apiKey)).GetChatClient(deploymentModel);
// Display the application header
ConsoleHelper.ShowHeader();
// create a list of chat messages
List<ChatMessage> chatMessages = [];
// chat loop
while (true)
{
try
{
// Prompt the user for input without clearing the console
string userInput =
ConsoleHelper.GetString("Enter your message:", false);
// Add the user message to the ongoing chat history
chatMessages.Add(ChatMessage.CreateUserMessage(userInput));
// Print a separator and label for the AI response
Console.WriteLine();
Console.WriteLine("AI:");
// Send the chat history to the Azure OpenAI model for completion
ClientResult<ChatCompletion> result =
await chatClient.CompleteChatAsync(chatMessages);
// Extract the first response from the model output
string aiResponse =
result.Value.Content[0].Text;
// Display the AI's response in the console using Spectre.Console
// markup
ConsoleHelper.WriteToConsole(aiResponse);
// Add the AI's response to the chat history to maintain context
chatMessages.Add(ChatMessage.CreateAssistantMessage(aiResponse));
// Retrieve and display token usage information
ChatTokenUsage usage =
result.Value.Usage;
ConsoleHelper.WriteResponseInformation(
result.Value.Model,
usage.InputTokenCount,
usage.OutputTokenCount);
// Add extra spacing for the next input loop
Console.WriteLine();
}
catch (Exception ex)
{
// Handle and display any unexpected errors
// (e.g., network or API issues)
ConsoleHelper.WriteToConsole(
$"[red]An error occurred: {ex.Message}[/]");
Console.WriteLine();
}
}
/// <summary>
/// Prompts the user to enter endpoint, API key, and model name.
/// </summary>
/// <returns>A tuple containing endpoint, API key, and model name.</returns>
static (string Endpoint, string ApiKey, string ModelName) GetConfiguration()
{
string endpoint =
ConsoleHelper.GetUrl(
"Enter your [yellow]Azure OpenAI[/] endpoint:");
string apiKey =
ConsoleHelper.GetString(
"Enter your [yellow]Azure OpenAI[/] API key:");
string modelName =
ConsoleHelper.GetString(
"Enter your [yellow]Model Router[/] model name:");
return (endpoint, apiKey, modelName);
}App in Aktion
Beim Start der Anwendung wirst du durch einen kurzen Einrichtungsprozess geführt:
Gib zunächst deinen Azure OpenAI-Endpunkt ein.
Gib anschließend deinen Azure OpenAI API-Schlüssel ein.
Gib den Namen der Bereitstellung an – also den Namen deines konfigurierten Model Routers.
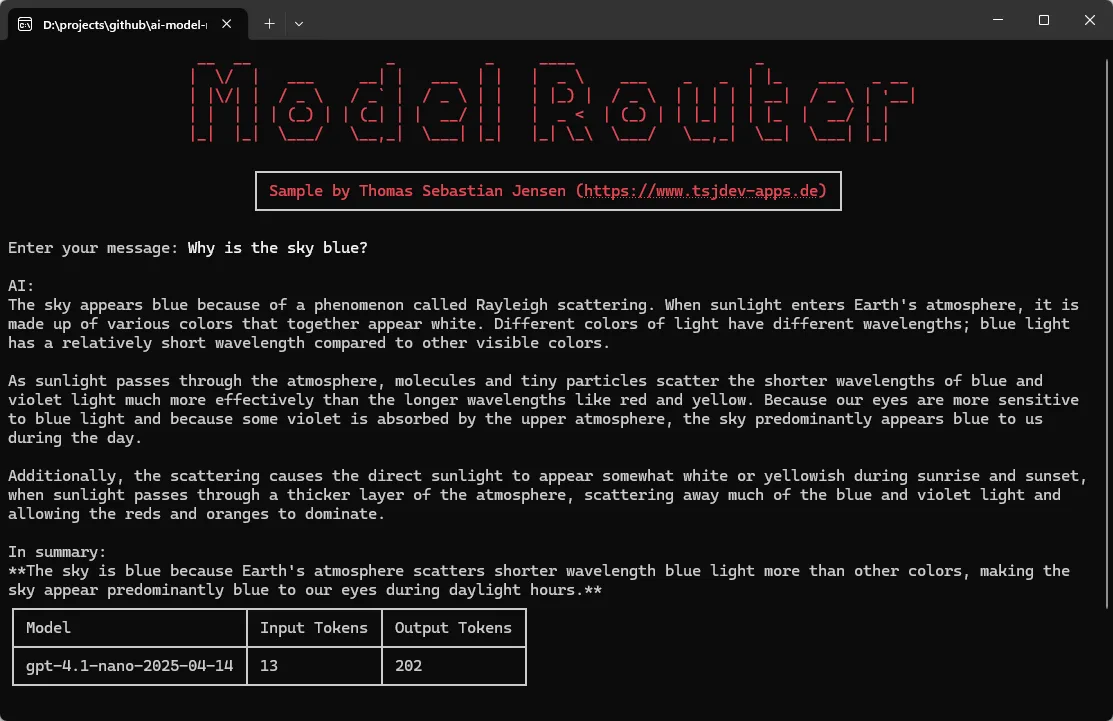
Probieren wir einen einfachen Prompt aus: Warum ist der Himmel blau?
Der Model Router leitet diese Anfrage an das Modell gpt-4.1-nano weiter, das daraufhin eine passende Erklärung liefert.
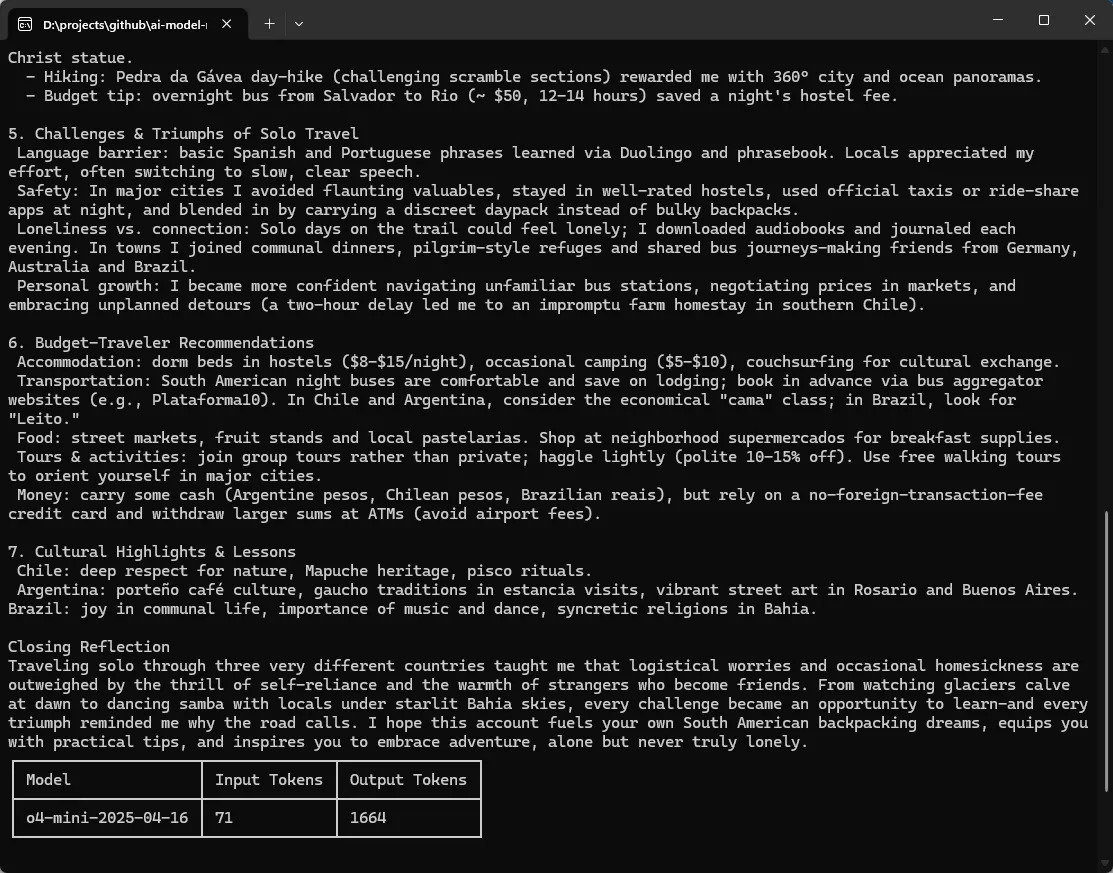
Versuchen wir nun einen komplexeren, offenen Prompt: „Schreibe einen ausführlichen Bericht über ein Solo-Backpacking-Abenteuer durch Südamerika – mit Stationen in Chile, Brasilien und Argentinien. Beschreibe die Herausforderungen und Erfolge des Alleinreisens, Begegnungen mit Einheimischen und die kulturelle Vielfalt, die du erlebt hast. Erwähne Highlights, besondere Erlebnisse wie Wanderungen und gib Tipps für Reisende mit kleinem Budget.“
In diesem Fall erkennt der Model Router die höhere Komplexität und wählt automatisch ein leistungsfähigeres Modell – z. B. o4-mini – um eine ausführliche, erzählerische Antwort zu generieren.
Wie du siehst: Der Model Router leitet deine Anfrage dynamisch an das passende Modell weiter – ganz ohne Code-Anpassungen.
Fazit
Der Model Router in Azure AI Foundry ermöglicht es Entwickler:innen, die Anwendungslogik von konkreten Modellen zu entkoppeln – ein leistungsstarker Ansatz, um KI-Workflows flexibel zu skalieren und anzupassen. In Kombination mit dem offiziellen C# SDK kannst du schnell, sicher und mit produktionsreifer Zuverlässigkeit loslegen.
Den vollständigen Quellcode – inklusive Program.cs und der ConsoleHelper-Klasse – findest du in meinem GitHub-Repository.


Verwendung von Ollama zur Ausführung lokaler LLMs auf deinem Computer
Read Article Cognitive Services: Alter einer Person ermitteln
Read Article