
Wenn du regelmäßig mit verschiedenen OpenAI-Modellen arbeitest, taucht sehr schnell eine Frage auf:
„Welches Modell sollte ich für diese Aufgabe benutzen?“ Latenz, Output-Qualität, Tokenverbrauch und Preis spielen alle eine Rolle — und meistens siehst du die echten Unterschiede erst dann, wenn du die Modelle nebeneinander ausprobierst. Also habe ich ein kleines Blazor-Server-Dashboard gebaut, das genau das macht: Ein Prompt rein → mehrere Modelle raus → Ergebnisse sauber nebeneinander.
Live-Demo: https://openaimodelcomparison.tsjdev-apps.de
🚀 Warum Blazor Server?
Ich wollte eine simple UI, ohne tonnenweise Client-Side-JavaScript.
Blazor Server hält eine persistente SignalR-Verbindung und lässt den Server die ganze Arbeit übernehmen:
- Parallele API-Calls
- Messung der Antwortzeiten
- Tokenzählung
- Kostenberechnung
Der Browser bleibt also schön leichtgewichtig — so wie es sein sollte.
Stack: .NET 10 + Radzen für schnellen UI-Aufbau.
⚙️ Konfiguration über JSON
Welche Modelle getestet werden und wie viel sie kosten, liegt in einer kleinen JSON-Datei. Preise sind angegeben in „per million tokens“, ganz wie im offiziellen OpenAI-Pricing.
[
{
"name": "gpt-5.1",
"displayName": "GPT-5.1",
"isSelected": false,
"inputPricePerMillionTokens": 1.25,
"outputPricePerMillionTokens": 10.0
},
{
"name": "gpt-4.1-mini",
"displayName": "GPT-4.1 mini",
"isSelected": false,
"inputPricePerMillionTokens": 0.40,
"outputPricePerMillionTokens": 1.60
}
]
Beim Start wandelt ein Konfigurationsservice die Datei in starke Typen um. Der Rest der App bleibt super clean — keine Dateien, kein JSON, nur Models.
🧱 Minimaler Startup-Code
Die Program.cs ist bewusst kompakt gehalten: Services registrieren, Razor Components mappen, fertig.
// Application entry point and service configuration
WebApplicationBuilder builder = WebApplication.CreateBuilder(args);
// Add Radzen Blazor components for UI
builder.Services.AddRadzenComponents();
// Add Razor components with interactive server-side rendering
builder.Services
.AddRazorComponents()
.AddInteractiveServerComponents();
// Register application services
builder.Services
.AddSingleton<IModelConfigurationService, ModelConfigurationService>();
builder.Services
.AddScoped<ISamplePromptService, SamplePromptService>();
builder.Services
.AddScoped<IOpenAIComparisonService, OpenAIComparisonService>();
WebApplication app = builder.Build();
// Map static assets and Razor components with interactive server rendering
app.MapStaticAssets();
app.MapRazorComponents<App>()
.AddInteractiveServerRenderMode();
// Start the application
app.Run();
⚡ Fan-Out: Ein Prompt → Viele Modelle
Dieser Service nimmt einen Prompt, schickt ihn an mehrere Modelle, wartet alle Antworten ab und liefert Latenz, Token-Stats und geschätzte Kosten zurück.
/// <summary>
/// Gets a response from a specific OpenAI model for the given usermessage.
/// </summary>
/// <param name="apiKey">The OpenAI API key for authentication.<param>
/// <param name="userMessage">The message to send to the model.<param>
/// <param name="model">The model to query.</param>
/// <param name="settings">Optional chat settings to customize
/// theAPI request.</param>
/// <returns>A comparison result containing the model's
/// responseand metrics.</returns>
private async Task<ModelComparisonResult> GetModelResponseAsync(
string apiKey,
string userMessage,
OpenAIModel model,
ChatSettings? settings)
{
await _throttler.WaitAsync();
Stopwatch stopwatch = Stopwatch.StartNew();
try
{
OpenAIClient client = new(apiKey);
ChatClient chatClient = client.GetChatClient(model.Name);
List<ChatMessage> messages =
[
new SystemChatMessage("You are a helpful assistant."),
new UserChatMessage(userMessage)
];
OpenAI.Chat.ChatCompletionOptions chatOptions = new()
{
MaxOutputTokenCount = settings?.MaxTokens,
Temperature = settings?.Temperature,
TopP = settings?.TopP,
FrequencyPenalty = settings?.FrequencyPenalty
};
ChatCompletion response = await chatClient
.CompleteChatAsync(messages, chatOptions);
stopwatch.Stop();
string content = response.Content[0].Text;
int inputTokens = response.Usage.InputTokenCount;
int outputTokens = response.Usage.OutputTokenCount;
double inputCost = (inputTokens / 1_000_000.0)
* model.InputPricePerMillionTokens;
double outputCost = (outputTokens / 1_000_000.0)
* model.OutputPricePerMillionTokens;
double totalCost = inputCost + outputCost;
return new ModelComparisonResult
{
ModelName = model.Name,
ModelDisplayName = model.DisplayName,
Response = content,
InputTokens = inputTokens,
OutputTokens = outputTokens,
TotalTokens = response.Usage.TotalTokenCount,
DurationInSeconds = stopwatch.Elapsed.TotalSeconds,
EstimatedCost = totalCost,
IsSuccess = true
};
}
catch (Exception ex)
{
stopwatch.Stop();
return new ModelComparisonResult
{
ModelName = model.Name,
ModelDisplayName = model.DisplayName,
Response = string.Empty,
InputTokens = 0,
OutputTokens = 0,
TotalTokens = 0,
DurationInSeconds = stopwatch.Elapsed.TotalSeconds,
EstimatedCost = 0,
IsSuccess = false,
ErrorMessage = ex.Message
};
}
finally
{
_throttler.Release();
}
}Zwei Dinge machen den Ansatz extrem nützlich:
- Stopwatch pro Anfrage
→ ehrliche Latenzwerte, nicht nur Serververarbeitungszeit. - Neutrales DTO
→ Die UI bleibt angenehm simpel und rein darstellend.
🖥️ Eine einfache, ehrliche UI
Das Ziel war nicht, den „UI-Preis des Jahres“ zu gewinnen, sondern Reibung zu entfernen: Modelle auswählen → Prompt eingeben → Button drücken → Antworten vergleichen.
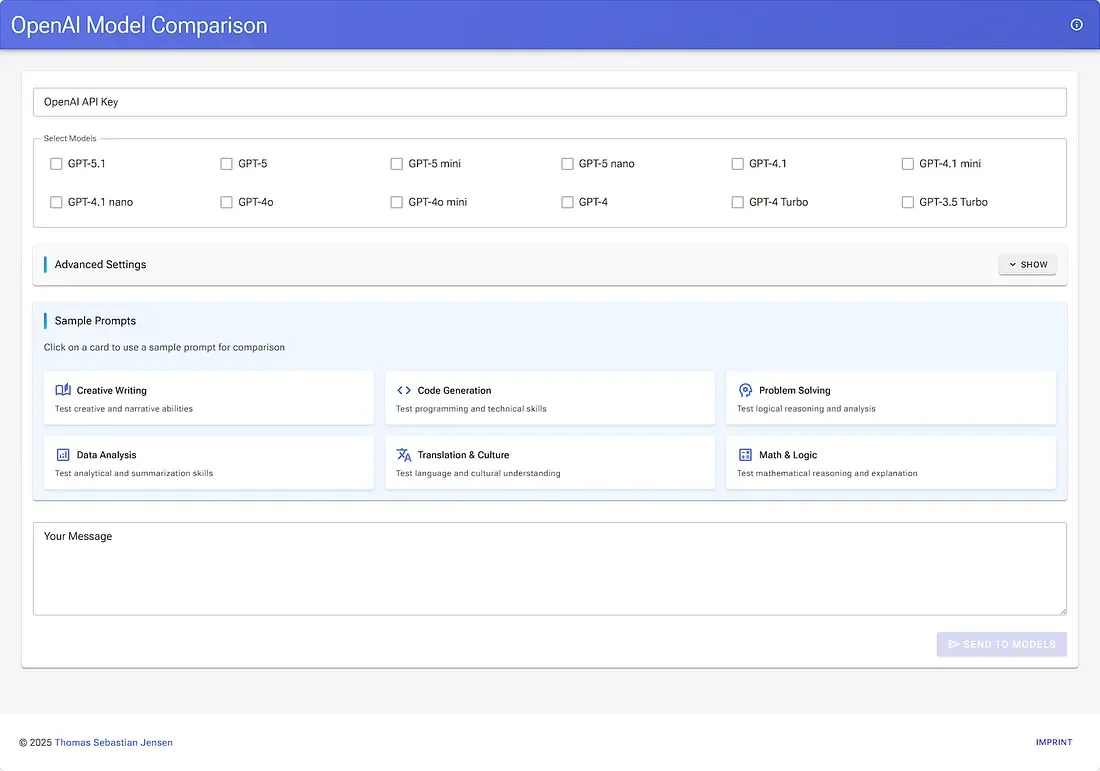
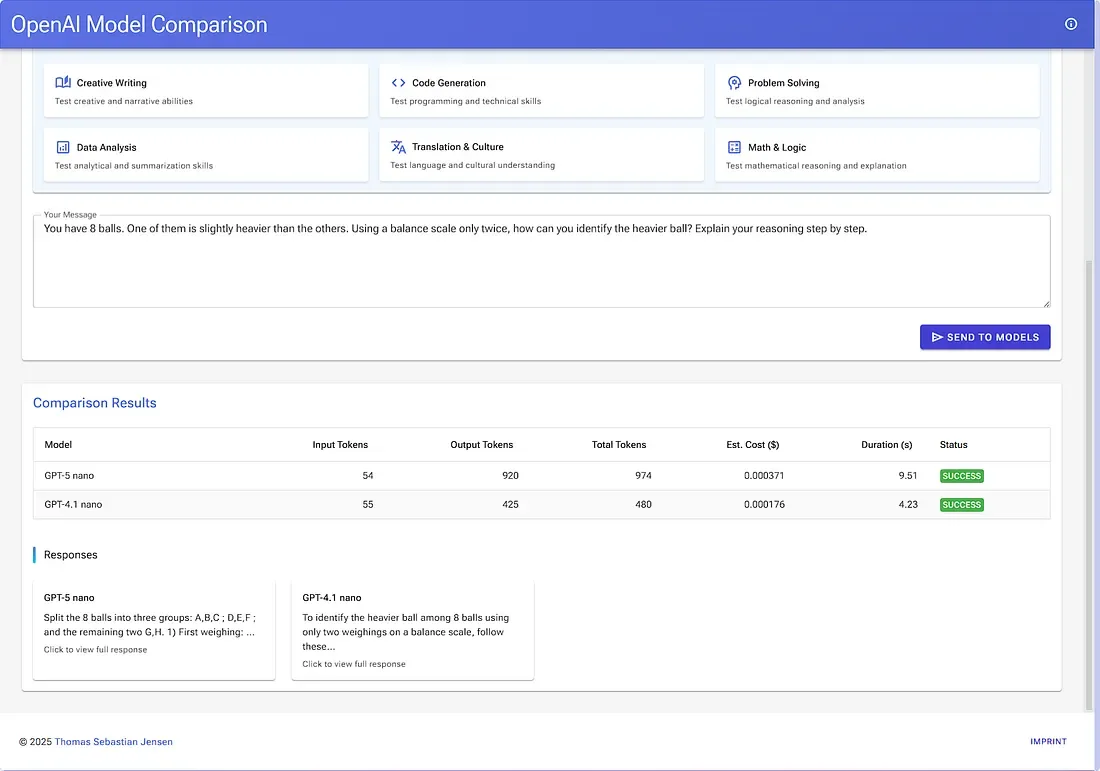
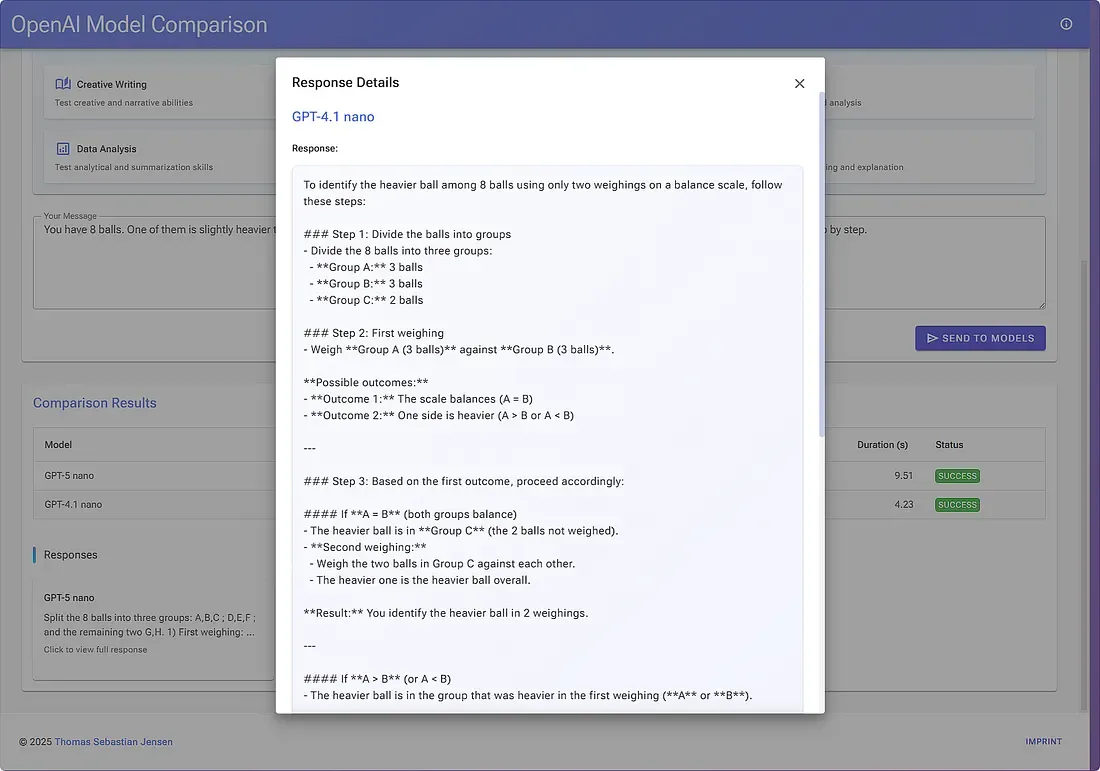
🛡️ Resilienz & Limits
Parallele Calls sind super — bis die Rate Limits zuschlagen.
Für produktive Nutzung solltest du:
- Retry mit Jitter einbauen
- Concurrency throttlen, wenn viele Modelle ausgewählt sind
- CancellationTokens durchreichen (Blazor Server liefert automatisch eins pro Anfrage)
Das schützt dich davor, dass ein Nutzer wegklickt und dein Server trotzdem wie wild weiterarbeitet.
🎯 Probier’s selbst
Live: https://openaimodelcomparison.tsjdev-apps.de
- Bring einfach deinen eigenen OpenAI API-Key mit.
- Repo klonen,
models.jsonanpassen - Zuschauen, wie Preis- und Verhaltensänderungen sofort sichtbar werden.
✨ Fazit
Das Dashboard ist klein, aber unglaublich hilfreich beim Experimentieren mit LLMs. Ob du Prompts tunst, Kosten einschätzt oder Latenz vergleichst — alle Antworten nebeneinander zu sehen liefert Einsichten, die du bei Einzelabfragen nie bekommst.


Erstellen einer neuen ASP.NET Core Blazor App
Read Article
Bereitstellen von Azure Open AI Services mit LLM Deployments mit Bicep
Read Article